什么是 Prometheus
Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud.
From metrics to insight. Power your metrics and alerting with a leading open-source monitoring solution.
Prometheus是新一代的监控系统解决方案,也是基于Golang的重量级云原生开源项目。
在容器化监控领域,Prometheus是不二之选,并且能兼容传统的监控方案。
从部署、使用到开发,我个人的感受是:
特点
- 开箱即用,使用门槛低
- 强大的开源社区和生态支持
- 通过PromQL实现多维度数据模型的灵活查询
- 灵活的自定义探针(如Exporter等),编写简单方便
- 时序数据库更契合监控场景
局限
- 不适合存储事件或者日志,更多地展示的是趋势性的监控,主要面向metrics
- 对策:使用Loki,他是面向log的类Prometheus系统,与Grafana同门
- 本地存储短期数据,不适合大量历史数据存储,这是设计初衷
- 对策:远程存储使用其他TSDB,如InfluxDB
- Exporter种类繁多,每个Exporter又相互独立、各司其职,Exporter越多,维护压力越大
- 对策:使用Telegraf集成Prometheus(Telegraf是用于数据收集的开源Agent,资源使用率更低)
Prometheus 的优势
Prometheus 的主要优势有:
- 由指标名称和和键/值对标签标识的时间序列数据组成的多维数据模型。
- 强大的查询语言 PromQL。
- 不依赖分布式存储;单个服务节点具有自治能力。
- 时间序列数据是服务端通过 HTTP 协议主动拉取获得的。
- 也可以通过中间网关来推送时间序列数据。
- 可以通过静态配置文件或服务发现来获取监控目标。
- 支持多种类型的图表和仪表盘。
Prometheus 的组件
Prometheus 生态系统由多个组件组成,其中有许多组件是可选的:
- Prometheus Server 作为服务端,用来存储时间序列数据。
- 客户端库用来检测应用程序代码。
- 用于支持临时任务的推送网关。
- Exporter 用来监控 HAProxy,StatsD,Graphite 等特殊的监控目标,并向 Prometheus 提供标准格式的监控样本数据。
- alartmanager 用来处理告警。
- 其他各种周边工具。
其中大多数组件都是用 Go 编写的,因此很容易构建和部署为静态二进制文件。
Prometheus主要由Prometheus Server、Pushgateway、Job/Exporter、Service Discovery、Alertmanager、Dashboard这6个核心模块构成。Prometheus通过服务发现机制发现target,这些目标可以是长时间执行的Job,也可以是短时间执行的Job,还可以是通过Exporter监控的第三方应用程序。被抓取的数据会存储起来,通过PromQL语句在仪表盘等可视化系统中供查询,或者向Alertmanager发送告警信息,告警会通过页面、电子邮件、钉钉信息或者其他形式呈现。
Pushgateway
Prometheus是Pull(拉取模式)为主的监控系统,它的推模式就是通过Pushgateway组件实现的。Pushgateway是支持临时性Job主动推送指标的中间网关,它本质上是一种用于监控Prometheus服务器无法抓取的资源的解决方案。
使用Pushgateway原因:
- Prometheus采用pull模式,可能由于不在一个子网或防火墙导致无法直接拉取各target数据
- 需要将不同数据汇总后,再由Prometheus统一收集
缺点:
- pushgateway宕机影响范围会更大。
- prometheus拉取状态up只针对pushgateway,无法做到对每个节点有效。
- pushgateway可以持久化推送给它的所有监控数据
Prometheus 的架构
Prometheus 的整体架构以及生态系统组件如下图所示:
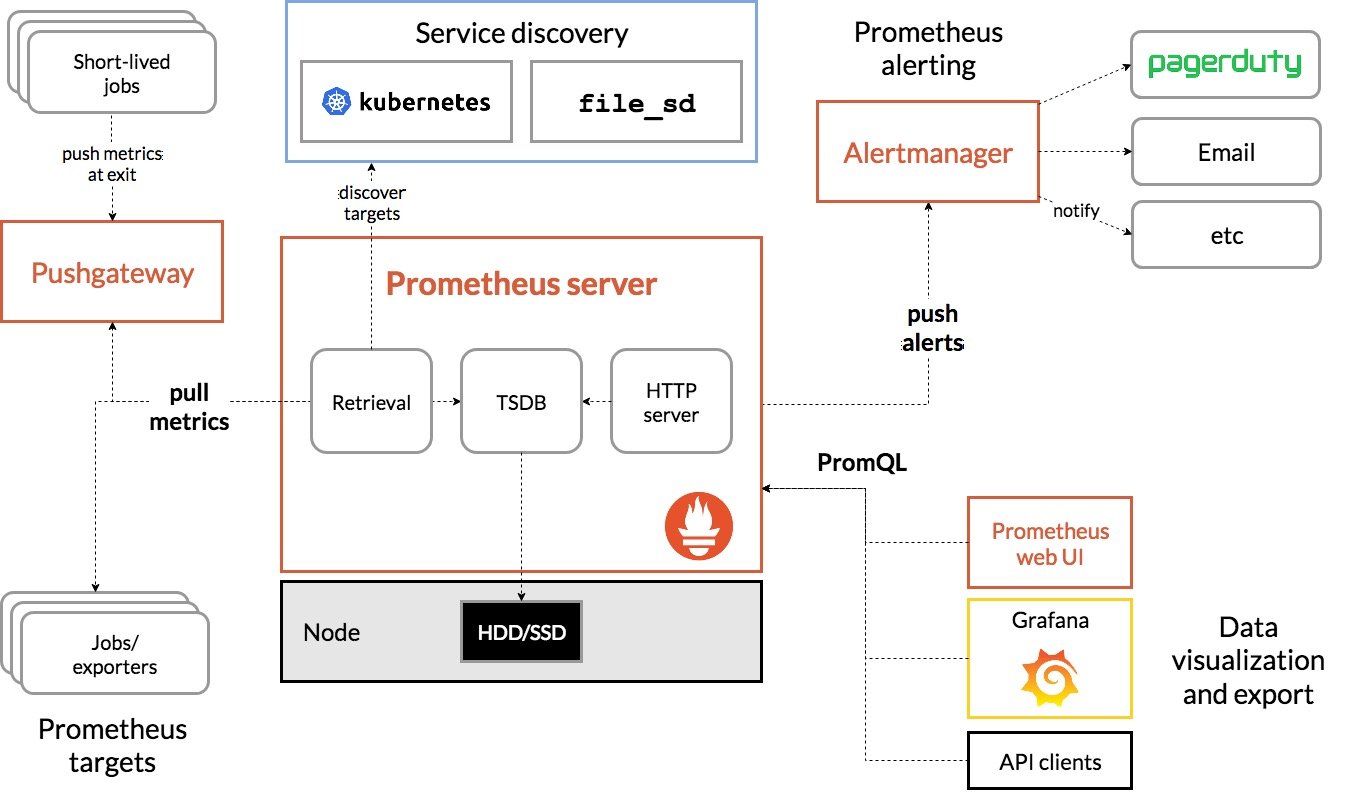
从上述架构图中可以看到,Prometheus不仅是一款时间序列数据库,在整个生态上还是一套完整的监控系统。对于时间序列数据库,在进行技术选型的时候,往往需要从宽列模型存储、类SQL查询支持、水平扩容、读写分离、高性能等角度进行分析。而监控系统的架构,往往还需要考虑通过减少组件、服务来降低成本和复杂性以及水平扩容等因素。
Prometheus Server 直接从监控目标中或者间接通过推送网关来拉取监控指标,它在本地存储所有抓取到的样本数据,并对此数据执行一系列规则,以汇总和记录现有数据的新时间序列或生成告警。可以通过 Grafana 或者其他工具来实现监控数据的可视化。
关于数据对接Grafana,可以看看上一篇博客
返回上一篇《Grafana数据可视化》Prometheus 适用于什么场景
Prometheus 适用于记录文本格式的时间序列,它既适用于以机器为中心的监控,也适用于高度动态的面向服务架构的监控。在微服务的世界中,它对多维数据收集和查询的支持有特殊优势。Prometheus 是专为提高系统可靠性而设计的,它可以在断电期间快速诊断问题,每个 Prometheus Server 都是相互独立的,不依赖于网络存储或其他远程服务。当基础架构出现故障时,你可以通过 Prometheus 快速定位故障点,而且不会消耗大量的基础架构资源。
Prometheus 不适合什么场景
Prometheus 非常重视可靠性,即使在出现故障的情况下,你也可以随时查看有关系统的可用统计信息。如果你需要百分之百的准确度,例如按请求数量计费,那么 Prometheus 不太适合你,因为它收集的数据可能不够详细完整。这种情况下,你最好使用其他系统来收集和分析数据以进行计费,并使用 Prometheus 来监控系统的其余部分。
参考资料:
prometheus/prometheus: The Prometheus monitoring system and time series database. (github.com)